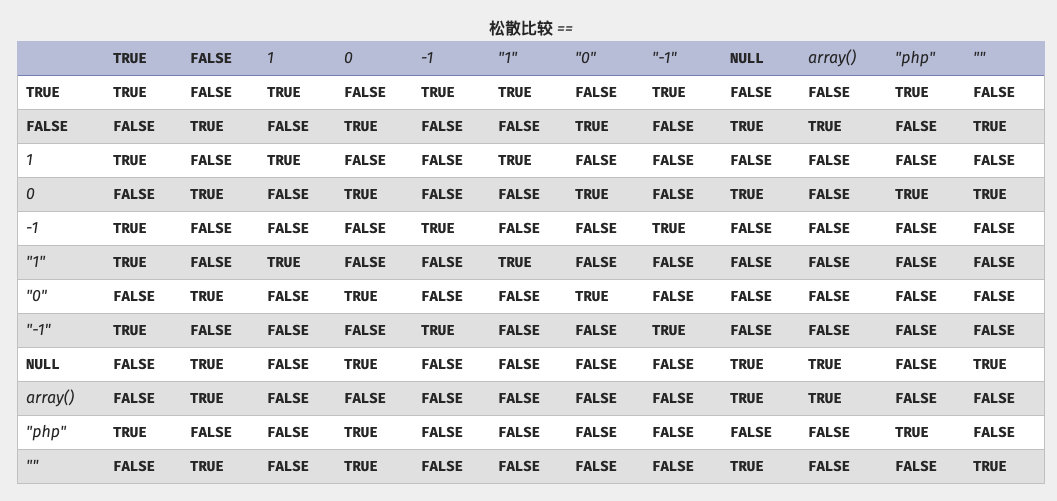
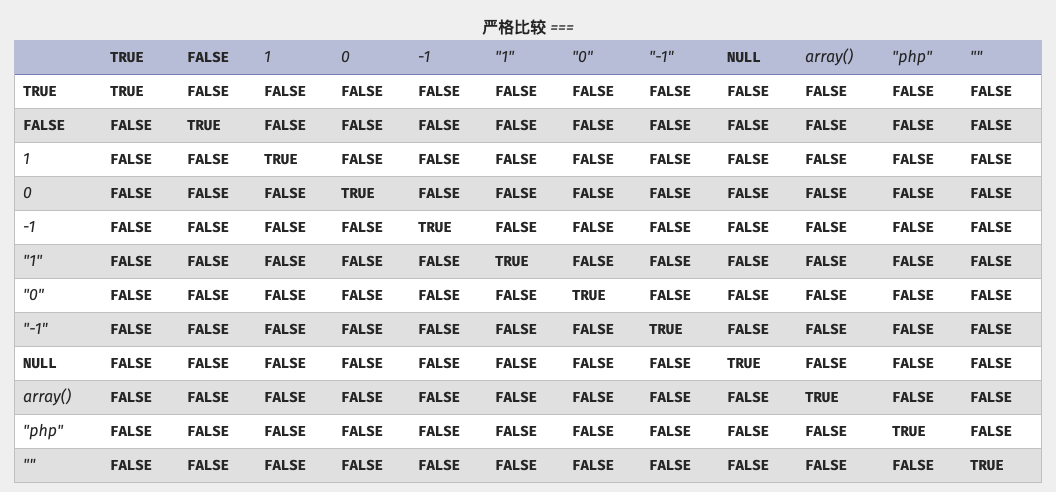
中0=='aa'的结果是true
看一段代码:
<?php
$arr = [0 => 1, 'aa' => 2, 3, 4];
foreach($arr as $key=> $val) {
echo $key == 'aa' ? 5 : $val;
}
?>
上面的代码输出结果是什么?
// 正确答案
5534
为什么是5534呢, 难道系统出语言出BUG了, 怎么会 aa 也会等于0呢.
这里就牵扯到php里的类型转换规则
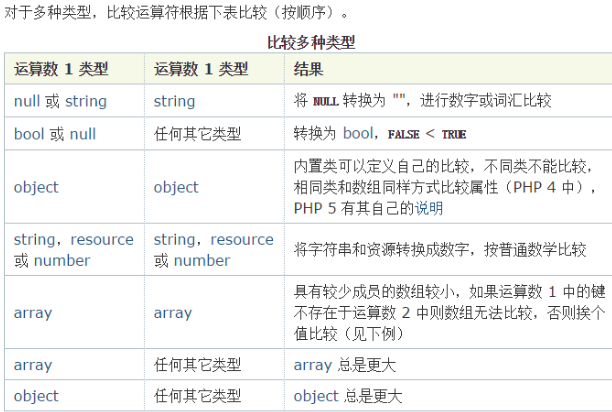
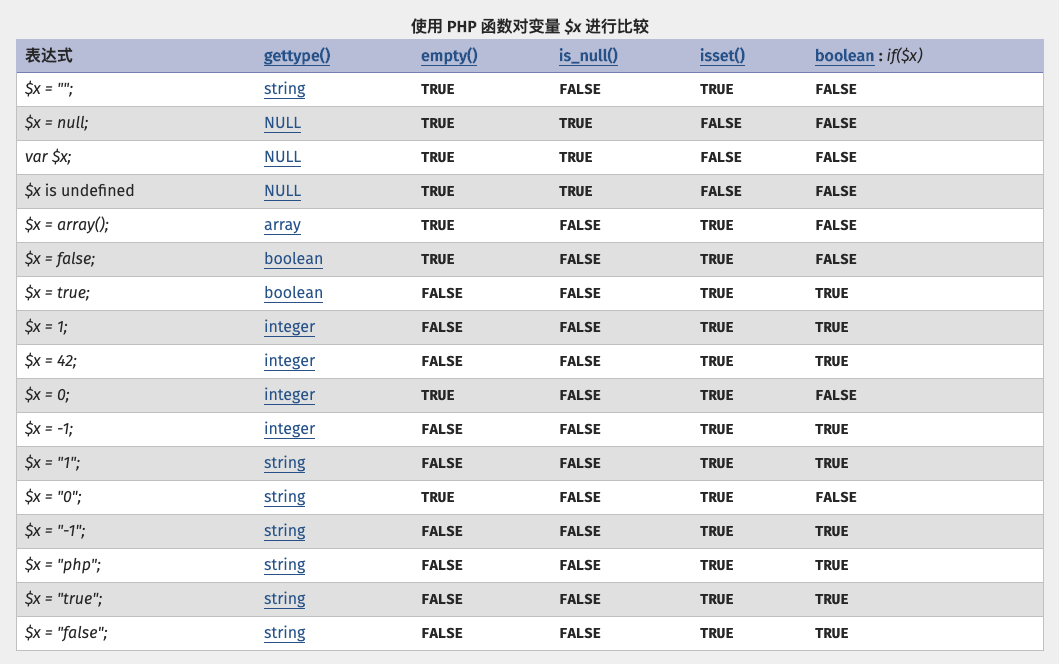
- 如果一个数字和一个字符串比较, 那么会把字符串转换成数字在进行比较.
- 字符串的转换法则, 若字符串以数字开头,则取开头的数字,直到不为数字的地方的位置. 若无数字, 则值为0. (根据数据类型,编译器自动选择转换类型, 比如: int float).
<?php
var_dump(1234 == "1234a"); //true
var_dump(1234 == "1234.01a"); // false
var_dump(1234.0 == "1234a"); // true
var_dump(1234.01 == "1234.01a"); // true
?>
关于PHP浮点数之 intval((0.1+0.7)*10) 为什么是7
为啥输出是57啊? PHP的bug么?
我相信有很多的同学有过这样的疑问, 因为光问我类似问题的人就很多, 更不用说bugs.php.net上经常有人问…
要搞明白这个原因, 首先我们要知道浮点数的表示(IEEE 754):
浮点数, 以64位的长度(双精度)为例, 会采用1位符号位(E), 11指数位(Q), 52位尾数(M)表示(一共64位).
符号位:最高位表示数据的正负,0表示正数,1表示负数。
指数位:表示数据以2为底的幂,指数采用偏移码表示
尾数:表示数据小数点后的有效数字.
这里的关键点就在于, 小数在二进制的表示, 关于小数如何用二进制表示, 大家可以百度一下, 我这里就不再赘述, 我们关键的要了解, 0.58 对于二进制表示来说, 是无限长的值(下面的数字省掉了隐含的1)..
0.58的二进制表示基本上(52位)是: 0010100011110101110000101000111101011100001010001111
0.57的二进制表示基本上(52位)是: 0010001111010111000010100011110101110000101000111101
而两者的二进制, 如果只是通过这52位计算的话,分别是:
0.58 -> 0.57999999999999996
0.57 -> 0.56999999999999995
至于0.58 * 100的具体浮点数乘法, 我们不考虑那么细, 我们就模糊的以心算来看 0.58 * 100 = 57.999999999
那你intval一下, 自然就是57了….
可见, 这个问题的关键点就是: “你看似有穷的小数, 在计算机的二进制表示里却是无穷的”
so, 不要再以为这是PHP的bug了, 这就是这样的…..
原文
foreach内两次迭代引用时引发的问题
<?php
$arr = [1,2,3];
foreach($arr as &$v) {
//nothing todo.
}
foreach($arr as $v) {
//nothing todo.
}
var_export($arr);
//output:array(0=>1,1=>2,2=>2),你的答案对了吗?为什么
?>
标准的写法:在使用了“ & ”的 foreach 之后,需要写一句 unset(v
的后果就是,在第一次迭代以后,arr[2]的位置, 所以, 后面每次迭代都是对$v`的赋值.
过程:
$v = &$arr[0];
$v = &$arr[1];
$v = &$arr[2];
//var_dump($arr);
//请注意,从这个时候开始,$v和$arr[2]是等价的
$v = $arr[0];
$v = $arr[1];
$v = $arr[2];
//var_dump($arr);
其次 :
php是没有块级作用域的!!!
第一个循环结束后,$item依然指向数组的第三个成员。
之后每次循环,就把数组的第一个值写到第三个成员,然后是第二个值写个第三个成员,然后是第三个值写到第三个成员,但此时第三个值已经被上次修改成2了,所以这次第三个值会被修改成2.
读取一个超大的日志文件
常规操作中,如果需要读取一个超大文件需要直接file_get_contents,加载到内存里, 这样在小文件操作是完全可行的, 但是大文件如果这样读取,那么导致内存溢出. 怎么才能用PHP读取一个超大的文件呢.
没错, 使用PHP的生成器, 即yield.
看下面生成器代码:
<?php
function createRange($number){
for($i=0;$i<$number;$i++){
yield time();
}
}
$result = createRange(10); // 这里调用上面我们创建的函数
foreach($result as $value){
sleep(1);
echo $value.'<br />';
}
?>
我们来还原一下代码执行过程。
- 首先调用
createRange函数,传入参数10,但是for值执行了一次然后停止了,并且告诉foreach第一次循环可以用的值。 - foreach开始对$result循环,进来首先
sleep(1),然后开始使用for给的一个值执行输出。 - foreach准备第二次循环,开始第二次循环之前,它向for循环又请求了一次。
- for循环于是又执行了一次,将生成的时间戳告诉foreach.
- foreach拿到第二个值,并且输出。由于
foreach中sleep(1),所以,for循环延迟了1秒生成当前时间
所以,整个代码执行中,始终只有一个记录值参与循环,内存中也只有一条信息。
无论开始传入的$number有多大,由于并不会立即生成所有结果集,所以内存始终是一条循环的值。
概念理解
到这里,你应该已经大概理解什么是生成器了。下面我们来说下生成器原理。
首先明确一个概念:生成器yield关键字不是返回值,他的专业术语叫产出值,只是生成一个值
那么代码中foreach循环的是什么?其实是PHP在使用生成器的时候,会返回一个Generator类的对象。foreach可以对该对象进行迭代,每一次迭代,PHP会通过Generator实例计算出下一次需要迭代的值。这样foreach就知道下一次需要迭代的值了。
而且,在运行中for循环执行后,会立即停止。等待foreach下次循环时候再次和for索要下次的值的时候,for循环才会再执行一次,然后立即再次停止。直到不满足条件不执行结束。
所以可以这样操作超大的日志:
<?php
header("content-type:text/html;charset=utf-8");
function readTxt()
{
# code...
$handle = fopen("./test.txt", 'rb');
while (feof($handle)===false) {
# code...
yield fgets($handle);
}
fclose($handle);
}
foreach (readTxt() as $key => $value) {
# code...
echo $value.'<br />';
}
使用生成器读取文件,第一次读取了第一行,第二次读取了第二行,以此类推,每次被加载到内存中的文字只有一行,大大的减小了内存的使用。
这样,即使读取上G的文本也不用担心,完全可以像读取很小文件一样编写代码。